
Abstract
본 논문은 물체 감지기술은 인공지능 분야의 기반으로, YOLO(You Only Look Once) 알고리즘과 이후의 발전해나간 버전에 대한 개요를 제공하는 논문이다.
본 논문에서 다루고자 하는 내용은 다음과 같다.
- YOLO 버전과 CNN의 공통점과 유사성
- YOLO 알고리즘의 개발과정 및 대상 인식 방법
Introduction
YOLO(You Only Look Once)는 다양하고 넓게 사용되는 알고리즘이며, 물체를 감지하는 특성으로 유명한 알고리즘이다.
- YOLO는 V1,V2,~V6까지, VOLO-LITE와 같은 제한된 버전 또한 존재한다
- 본 논문은 제한된 버전이 아닌 YOLO v1~v5까지의 버전에 초점을 맞추고자 하였다.
- YOLO의 개념, 구현, 5개 버전의 주요 차이를 비교하고자 한다.
YOLO 알고리즘의 발전
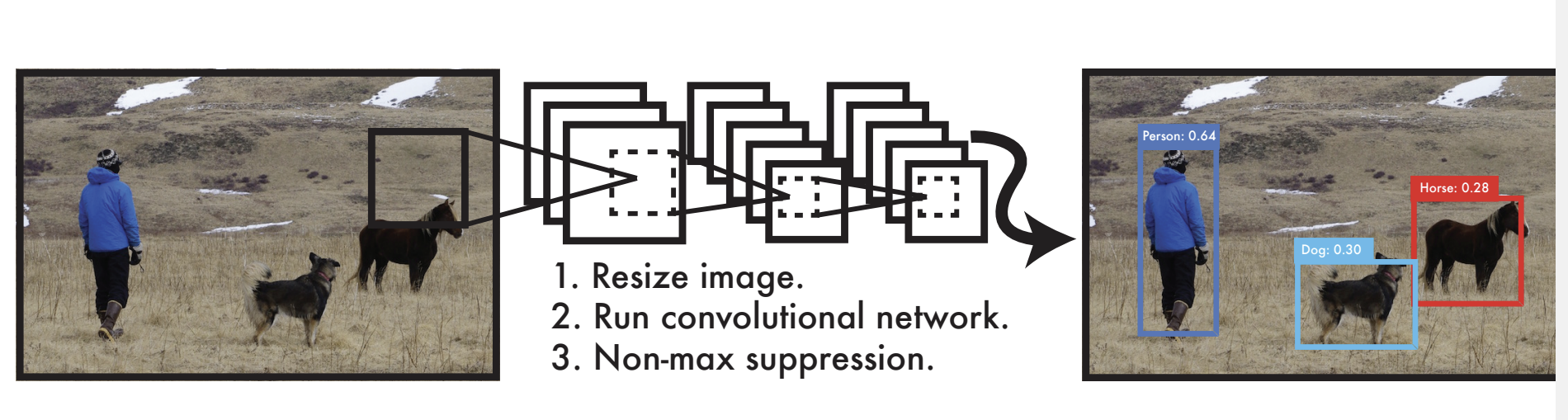
주요 차이점
YOLO의 핵심 → 작은 크기의 모델이지만, 빠른 계산속도를 보인다
- YOLO의 구조
- 신경망을 통해 경계상자의 위치와 범주를 출력할 수 있다.
- 네트워크에 사진을 넣어 → 최종 검출결과를 얻을 수 있다.
- ⇒ 이때, YOLO는 영상 시간 검출을 빠르게 할 수 있다.
- YOLO → global image를 직접 사용한다.
- 직접 사용하면서 글로벌 정보를 인코딩하고, 배경을 객체로 탐지하는 오류를 줄일 수 있다.
- YOLO → 다른 분야와도 접목이 가능하다 ⇒ 즉 일반화 능력이 강하다.
- 객체 탐지 문제를 회귀 문제로도 접근하여 탐지 정확도 개선은 필요하다.
- 특히, YOLO의 테스트는 비슷한 그룹의 객체에 좋지 않다.
- ⇒ 실제로는 같은 범주의 클래스에 속하나, grid가 2개의 상자만 예측되고 비정상적인 비율로 나타나면서 일반화 능력이 약해지는 것을 보인다
- 손실함수 → 위치 결정 오류로 검출 효율을 향상시킨다
- 크고 작은 물체에 따른 취급을 강화할 필요가 존재한다
- ⇒ 이러한 측면에 대한 균형을 잘 이루도록 손실함수를 설계해야 한다.
- YOLO → 여러 하위 샘플링 계층을 사용한다.
- 딥러닝 네트워크에서 학습된 대상 기능이 완전하지 않다 → 따라서, 하위 샘플링 계층을 통해 탐지 효과를 향상시킨다.
- 기존의 YOLO → 24개의 conv layer, 2개의 FCN으로 구성
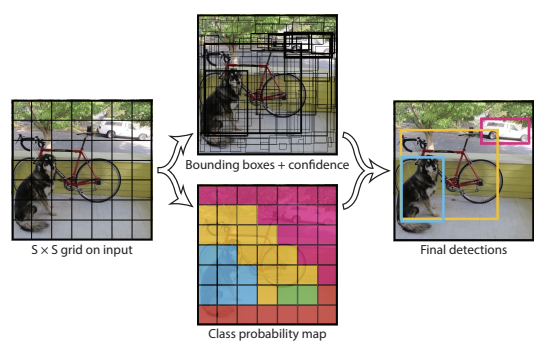
- Grid cell당 여러개의 경계 상자를 예측한다.
- 이때, 가장 높은 IOU(Intersection Over Union)를 갖는 경계 상자가 선택된다.
YOLO의 두가지 문제점
👉 위치가 부정확 하다
👉 Area Recommendation에 기반한 방법에 의해서는 Recall이 낮다
⇒ 따라서 YOLO v2는 두가지 측면을 개선하며, 네트워크를 깊고 넓히는것이 아닌 단순화하여 향상되고 빨라진 속도를 보이게 된다.
개선 요소
Batch normalization
- 각 레이어의 입력을 표준화해 수렴 속도를 높이고, 손실을 삭제했다.
⇒ mAP를 2% 증가시키는 것에 해당한다.
High-resolution classifier
- 기존의 YOLO 네트워크 → train 전 224 x 224 pixel 사용 후, 다음 detection에 448 x 448 pixel을 사용하였다.
- classification 모델에서 detection 모델로 전환 시 모델은 classification에 적응한다.
⇒ V2의 경우, 처음부터 224×224(160 에포크) 픽셀로 네트워크를 교육한 다음 픽셀을 448×448로 조정하고 10 에포크에 대해 교육하는 두 단계로 나뉩니다.
Fine features
- 레이어를 추가한다
- 해당 레이어의 기능 → 이전 레이어의 26x26 피쳐 맵을 이 레이어의 13x13 피쳐 맵과 연결하는 것이다.
- ⇒ 해당 레이어를 통해, 작은 물체 예측에 효과를 보였다
- 작은물체 → 여러 층의 conv를 병합하면 사라질 수 있어서, 이전 계층의 큰 기능들이 병합되어야 한다.
Multi-scale training
- 해당 train 방법은 동일한 네트워크여도, 다른 해상도의 이미지를 감지할 수 있도록 한다
- 입력 크기 클 때 → 훈련 속도가 느리다
- 입력 크기가 작을 때 →훈련 속도가 빠르다
- ⇒ 정확도와 속도의 균형이 잘 잡히게 된다.
속도 측면
Darknet-19
- YOLO 네트워크 → GooleNet을 기반으로 한다
- YOLO V2 → Darknet-19를 기본 네트워크로 변경하였다.
- 19개의 Conv layer, 5개의 FCN을 포함하여 구성
- GooleNet → 24개 Conv layer, 2개 FCN
- YOLO V2 → Darknet-19를 기본 네트워크로 변경하였다.
- Average Pooling Layer → 예측을 위해 FCN을 대체하고자 하용하였다.
Training for Classification
- 여기서의 훈련 → imageNet에 대한 사전 훈련 과정이다.
👉 dataset → ImageNet을 사용하고, 160 Epoch가 훈련, 224 x 224 입력 이미지 크기, learning rate는 0.1이 된다.
👉 훈련 과정 중에는 임의 자르기, 회전, 채도 및 밝기 조정과 같은 data increment가 사용된다.
👉 이후 데이터를 미세조정 한다. → 이때 448×448 입력을 사용하면 에포크와 학습 속도를 제외한 모든 매개 변수가 변경되지 않는다.
👉 여기서 학습률을 0.001로 변경하고, 10회에 걸쳐 훈련을 실시한다.
👉 결과는 미세 조정 후 top-1과 top-5의 정확도가 각각 76.5%와 93.3%임을 보여준다. ⇒ 기존 훈련 방식에 따르면 다크넷-19의 top-1과 top-5의 정확도는 72.9%, 91.2%다.
Training for Detection
구조적 측면
- 마지막의 Conv Layer를 삭제하고, 3개의 Convolution layer 33을 추가한다.
- 각 Conv Layer → 1024개의 필터를 갖고, 각각은 11개의 Conv Layer에 연결되어 있다.
- 해당 셀에 해당하는 두 박스의 카테고리 확률은 같지만, V2에서는 확률이 박스에 속하고, 각 박스는 grid가 아닌 카테고리 확률에 해당하게 된다.
- V2 vs V3
- 객체 감지를 위한 다중 스케일 기능이 도입되었다
- 기본적인 네트워크 구조를 조정하는 두가지 점을 가진다.
- YOLO v3 → 3가지 척도의 feature graph를 채택한다
- 입력값이 (416×416), (13×13), (26×26), (52×52).
- YOLO V3 → 각 위치에 3개의 prior boxes를 사용한다.
👉 K-means를 사용하여 9개의 prior boxes를 가져와 3개의 스케일 피쳐 맵으로 나눈다.
👉 더 큰 축척이 있는 피쳐 맵은 더 작은 이전 box를 사용한다.- YOLO V3 특징 추출 네트워크 →
residual model을 사용하였다.- V2가 사용한 Darknet-19와 비교하여 53개의 컨볼루션 레이어를 포함하고 있어 Darknet-53으로 불렸다.
YOLO v4
- YOLOv4 → 데이터 비교에 집중하여 개선하였다.
- YOLO V4=MARK Darknet 53+SPP+Pan+YOLO V3
- 주요 특징
- 효율적이고 강력한 Object Detection 모델을 제안하였다.
- 초고속으로 정확하게 탐지하도록 하였다.
- SOTA's bag-of-freebies and bag-of-specials 방법의 영향이 detector training에 검증되었다.
- CBN, PAN, SAM 등을 포함하여 단일 GPU 교육에 적합하고 효율적으로 SOTA 방법을 개선했다.
- V3에서는 하나의 Anchor point가 ground truth를 담당했지만, V4에서는 여러개의 앵커가 Ground Truth를 담당하고 있다.
- 앵커 프레임 수에는 변함이 없지만, 양성 샘플과 음성 샘플의 불균형이 완화된다
CIOU(Complete Intersection over Union)손실 함수를 채택하여 빠르게 수렴하여 문제를 제거할 수 있다.
YOLO V5
- 여러 네트워크 아키텍쳐에 대한 사용이 유연하고, 모델 크기가 가볍다
- 가볍더라도, YOLO v5와 동등하다
- PyTorch 프레임워크를 사용해, 데이터셋 훈련에도 용이하다.
- v4의 Darknet보다 product 투입에 쉽다
- 읽기 쉬운 코드로 학습에 도움이 된다
- 모델 train이 쉽고, batch reasoning은 실시간 결과를 생성한다.
즉, YOLO v5는 Data Loader를 통해 Train Data Batch를 제공하고, Train Data를 동시에 향상한다.
- Data Loader → 스케일링, 색 공간 조정 및 모자이크 향상의 세 가지 유형의 데이터 향상을 수행한다.
v1~v5까지의 YOLO 변화
V1: Grid division은 detection과 confidence loss를 책임진다V2: k-means가 추가되었으며, 2단계 훈련으로 진행되고 full convolution network 구조를 갖는다.V3: FPN을 이용해 다중 스케일을 검출하였다.V4: SPP, MISH 활성화 기능, 데이터 향상 Mosaic/Mixup, GIOU(Generalized Intersection over Union) 손실 기능V5: 모델 크기의 유연한 제어, Hardswish 활성화 기능 적용, 데이터 강화.
Relationship
- YOLO, YOLOv2 → 작은 표적을 탐지하는 데에는 효과적이지 않다.
- V3에 다중 스케일 탐지가 추가되어 좋은 평가를 받았다
- YOLOv4 → 전체 프로세스에서 가능한 모든 최적화를 분류하고 시도해 최상의 효과를 보였다
- 이는 EfficientDet보다 2배 더 빠르게 실행되며 비슷한 성능을 제공한다.
- YOLOv3의 AP와 FPS가 각각 10%, 12% 향상되었다
- YOLOv5는 →10+M에서 200+M까지 유연하게 모델을 제어할 수 있으며, 가벼운 모델이다.
- YOLO V3에서 YOLO V5까지의 전체 네트워크 다이어그램은 유사하지만, 세 가지 다른 척도에서 서로 다른 크기의 물체를 탐지하는 데도 초점을 맞추고 있다.
https://www.sciencedirect.com/science/article/pii/S1877050922001363
보안 전공 개발자지만 대학로에서 살고 싶어요
포스팅이 좋았다면 "좋아요❤️" 또는 "구독👍🏻" 해주세요!